Raspberry Pi 3 Model Bで音声合成して TTS出力する
from https://www.pcmarket.com.hk/2018/06/01/raspberry-pi-%E6%89%93%E6%8B%9B%E5%91%BC-remindbot-%EF%BC%88%E4%BA%8C%EF%BC%89/





from http://www.neko.ne.jp/~freewing/raspberry_pi/raspberry_pi_3_text_to_speach/
● Raspberry Pi 3 Model Bで音声合成して TTS出力する
まずは、音声出力のスピーカの動作の確認から。
音声出力の音量の設定
$ alsamixer
音声出力 自動
$ amixer cset numid=3 0
音声出力 ヘッドホンジャック
$ amixer cset numid=3 1
音声出力 HDMI
$ amixer cset numid=3 2
※ HDMIから音声が出ない場合は config.txtの # hdmi_driver=2の行の #を取る。
※行の先頭の #を取る。
# hdmi_driver=2
を
hdmi_driver=2
にする。
スピーカーのテスト
$ speaker-test -t sine -f 800
サウンドの再生確認
$ aplay /usr/share/sounds/alsa/Front_Center.wav
$ aplay /usr/share/sounds/alsa/Noise.wav
● Raspberry Pi 3 Model Bで英語の音声合成を使用して英語を出力する
英語のTTS、English Text to Speech
RPi Text to Speech (Speech Synthesis)
を参考にしました。
● Festival Text to Speech
$ sudo apt-get -y install festival
$ echo "Please note that these documents are a work in progress." | festival --tts
● Espeak Text to Speech
$ sudo apt-get -y install espeak
$ espeak -ven+f3 -k5 -s150 "Please note that these documents are a work in progress."
● Pico Text to Speech
$ sudo apt-get -y install libttspico-utils
$ pico2wave -w sample.wav "Please note that these documents are a work in progress." && aplay sample.wav
● Raspberry Pi 3 Model Bで中国語の音声合成を使用して中国語を出力する
中国語のTTS、Chinese Text to Speech
Ekho(余音) - 中文语音合成软件(支持粤语、普通话)
Ekho - Chinese text-to-speech software
GitHub hgneng/ekho
How to Install Ekho (for Linux and Raspberry Pi)
$ sudo apt-get -y install libsndfile1-dev libpulse-dev libncurses5-dev libestools2.1-dev festival-dev libmp3lame-dev
$ wget http://jaist.dl.sourceforge.net/project/e-guidedog/Ekho/6.5/ekho-6.5.tar.xz
$ tar xJvf ekho-6.5.tar.xz
$ cd ekho-6.5
$ ./configure --enable-festival
$ make CXXFLAGS=-DNO_SSE
$ sudo make install
$ ekho "hello 123 树莓派 中文语音合成"
$ ekho -h
● pa_simple_new() failed: Connection refusedエラーが出る場合
実行時に pa_simple_new() failed: Connection refusedエラーが出る場合は、
$ ./ekho "hello 123"
pa_simple_new() failed: Connection refused
pa_sample_spec(format=3,rate=16000,channels=ch=1)
Fail to init audio stream.
Fail to init sound.
pulseaudioを再インストールする。
$ sudo apt-get -y install pulseaudio
● googleの音声認識
wave形式で録音して flac形式に変換して Google音声認識 APIに渡す。
下記の www.google.com/speech-api/v1/recognizeは既に廃止となっているので使えない。
$ arecord -D "plughw:1,0" -d 5 file.wav
$ ffmpeg -i file.wav -ar 16000 -acodec flac file.flac
$ pacpl --overwrite -t flac file.wav
$ wget -q -U "Mozilla/5.0" -post-file file.flac -header "Content-Type: audio/x-flac; rate=16000" -O - "http://www.google.com/speech-api/v1/recognize?lang=zh-cn&client=chromium"
GitHub pranavrc/audio-transcribe
$ sudo apt-get -y install pacpl
$ wget https://github.com/pranavrc/audio-transcribe/raw/master/speech.py
$ wget https://github.com/pranavrc/audio-transcribe/raw/master/softkitty.wav
$ python ./speech.py softkitty.wav
softkitty.flac
Unable to connect
Reverse Engineering Google's Speech To Text API (v2)
現在利用 eSpeak 軟件讀出中文字,要做到這一點,必須為 Raspberry Pi 安裝中文環境的套件,包括中文字型與中文輸入法。只需在 Terminal 輸入下面的指令,就可以安裝有關的套件。

在指令中輸入: sudo apt-get install fonts-arphic-uming scim scim-chewing
指令中,最後的「 scim-chewing 」是一個名為「新酷音」的輸入法,如果想安裝倉頡或速成等輸入法,可將最後的「 scim-chewing 」改為「 scim-tables-zh 」套件。完成安裝後,重新啟動電腦,在桌面會出現一個輸入法的圖示,讓我們選擇不同的輸入法。

完成安裝後,重新啟動電腦,在桌面會出現一個輸入法的圖示,讓我們選擇不同的輸入法。
安裝 eSpeak 讀出中文
在習作中,負責合成和輸出語音的軟件是 eSpeak ,在這裡先為大家介紹一下這個軟件。 eSpeak 是一個語音合成( Text-To-Speech TTS )軟件,顧名思義就是把文字轉換成語音。除了英語外,還支援其它多種語言,並可以調節語音朗讀的速度,和選擇不同的聲音特質,如男性或女性的聲音,作為最後的合成語音。
在 Raspberry Pi 中使用 eSpeak ,只要簡單地在 Terminal 輸入指令列便可。另外,我們可以與其他感應器配合使用,並且編寫 Python 程式,呼叫 eSpeak 軟件,用來製作一個完整的習作。
Step 1
輸入指令 sudo apt-get install espeak
安裝 eSpeak 軟件的方法非常簡單,只要在 Terminal 中輸入指令: sudo apt-get install espeak
Step 2
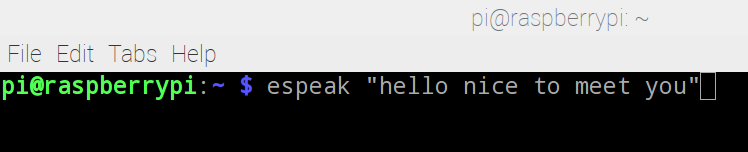
輸入測試指令 espeak“hello nice to meet you”
完成後,就可以使用 eSpeak 軟件,在 Terminal 中輸入下列的測試指令: espeak“hello nice to meet you”
Step 3
按下 Enter 鍵後, Raspberry Pi 便會透過連接著的喇叭,說出英語句子。如果想選擇不同的女性或男性聲音,可在指令中加入例如 -v f5 等參數, Raspberry Pi 便會以女性的聲音說出英語句子:Espeak –v f5
“hello nice to meet you”
“hello nice to meet you”
你可以選擇 5 種女性的聲音( f1-f5 ),或7種男性聲音( m1-m7 );另外還有 croak klatt 或 whisper 等不同的朗讀聲調效果。
Step 4
我們亦可以控制朗讀的速度,可在指令中加入例如 -s 80 等參數,改變朗讀的速度: Espeak –v f5 –s 80“hello nice to meet you”
在上述的指令中,明顯地發現朗讀的速度,是比一般情況為慢。
明白上述資料,我們就可以為 RemindBot 選擇適合的聲音特質和朗讀速度。
from http://www.neko.ne.jp/~freewing/raspberry_pi/raspberry_pi_3_text_to_speach/
● Raspberry Pi 3 Model Bで音声合成して TTS出力する
まずは、音声出力のスピーカの動作の確認から。
音声出力の音量の設定
$ alsamixer
音声出力 自動
$ amixer cset numid=3 0
音声出力 ヘッドホンジャック
$ amixer cset numid=3 1
音声出力 HDMI
$ amixer cset numid=3 2
※ HDMIから音声が出ない場合は config.txtの # hdmi_driver=2の行の #を取る。
※行の先頭の #を取る。
# hdmi_driver=2
を
hdmi_driver=2
にする。
スピーカーのテスト
$ speaker-test -t sine -f 800
サウンドの再生確認
$ aplay /usr/share/sounds/alsa/Front_Center.wav
$ aplay /usr/share/sounds/alsa/Noise.wav
● Raspberry Pi 3 Model Bで英語の音声合成を使用して英語を出力する
英語のTTS、English Text to Speech
RPi Text to Speech (Speech Synthesis)
を参考にしました。
● Festival Text to Speech
$ sudo apt-get -y install festival
$ echo "Please note that these documents are a work in progress." | festival --tts
● Espeak Text to Speech
$ sudo apt-get -y install espeak
$ espeak -ven+f3 -k5 -s150 "Please note that these documents are a work in progress."
● Pico Text to Speech
$ sudo apt-get -y install libttspico-utils
$ pico2wave -w sample.wav "Please note that these documents are a work in progress." && aplay sample.wav
● Raspberry Pi 3 Model Bで中国語の音声合成を使用して中国語を出力する
中国語のTTS、Chinese Text to Speech
Ekho(余音) - 中文语音合成软件(支持粤语、普通话)
Ekho - Chinese text-to-speech software
GitHub hgneng/ekho
How to Install Ekho (for Linux and Raspberry Pi)
$ sudo apt-get -y install libsndfile1-dev libpulse-dev libncurses5-dev libestools2.1-dev festival-dev libmp3lame-dev
$ wget http://jaist.dl.sourceforge.net/project/e-guidedog/Ekho/6.5/ekho-6.5.tar.xz
$ tar xJvf ekho-6.5.tar.xz
$ cd ekho-6.5
$ ./configure --enable-festival
$ make CXXFLAGS=-DNO_SSE
$ sudo make install
$ ekho "hello 123 树莓派 中文语音合成"
$ ekho -h
Ekho text-to-speech engine.
Version: 6.5
Syntax: ekho [option] [text]
-v, --voice=VOICE
Specified language or voice. ('Cantonese', 'Mandarin', 'Hakka', 'Tibetan', 'Ngangien' and 'Hangul' are available now. Mandarin is the default language.)
-l, --symbol
List phonetic symbol of text. Characters' symbols are splited by space.
-f, --file=FILE
Speak text file. ('-' for stdin)
-o, --output=FILE
Output to file.
-t, --type=OUTPUT_TYPE
Output type: wav(default), ogg or mp3
-p, --pitch=PITCH_DELTA
Set delta pitch. Value range from -100 to 100 (percent)
-a, --volume=VOLUME_DELTA
Set delta volume. Value range from -100 to 100 (percent)
-r, --rate=RATE
Set delta rate (this scales pitch and speed at the same time). Value range from -50 to 100 (percent)
-s, --speed=SPEED
Set delta speed. Value range from -50 to 300 (percent)
--server
Start Ekho TTS server.
--request=TEXT
Send request to Ekho TTS server.
--port
Set server port. Default is 2046.
--version
Show version number.
-h, --help
Display this help message.
Please report bugs to Cameron Wong (hgneng at gmail.com)
● pa_simple_new() failed: Connection refusedエラーが出る場合
実行時に pa_simple_new() failed: Connection refusedエラーが出る場合は、
$ ./ekho "hello 123"
pa_simple_new() failed: Connection refused
pa_sample_spec(format=3,rate=16000,channels=ch=1)
Fail to init audio stream.
Fail to init sound.
pulseaudioを再インストールする。
$ sudo apt-get -y install pulseaudio
● googleの音声認識
wave形式で録音して flac形式に変換して Google音声認識 APIに渡す。
下記の www.google.com/speech-api/v1/recognizeは既に廃止となっているので使えない。
$ arecord -D "plughw:1,0" -d 5 file.wav
$ ffmpeg -i file.wav -ar 16000 -acodec flac file.flac
$ pacpl --overwrite -t flac file.wav
$ wget -q -U "Mozilla/5.0" -post-file file.flac -header "Content-Type: audio/x-flac; rate=16000" -O - "http://www.google.com/speech-api/v1/recognize?lang=zh-cn&client=chromium"
GitHub pranavrc/audio-transcribe
$ sudo apt-get -y install pacpl
$ wget https://github.com/pranavrc/audio-transcribe/raw/master/speech.py
$ wget https://github.com/pranavrc/audio-transcribe/raw/master/softkitty.wav
$ python ./speech.py softkitty.wav
softkitty.flac
Unable to connect
Reverse Engineering Google's Speech To Text API (v2)


留言
張貼留言