application architecture
from https://qiita.com/lobin-z0x50/items/39131a4f47ed7c5df443
最もコスパの良い3つの施作
変更に強いアーキテクチャとは、いくつもの概念や指標の組み合わせと、複雑な理論の上に成り立っている。
そういったいくつもの重要な概念のうち、最もコスパの良い(経験上これだけは絶対にゆずれない、費用対効果の高い)項目をあげるとすると、以下の三つだ。
そういったいくつもの重要な概念のうち、最もコスパの良い(経験上これだけは絶対にゆずれない、費用対効果の高い)項目をあげるとすると、以下の三つだ。
- 適切なモジュール分割
- 依存関係を一方向にする
- テストコード
誤解の無いよう再度断っておくが、この3つだけで変更に強いアーキテクチャが必ず実現できるというものではない。
上記は昨今のソフトウェアの大規模化やフレームワークの流行、実装方式のトレンドなどを鑑みて、ソフトウェア設計者が最も考慮すべきで最も効果の高い項目、といった位置づけで選出したものある。
上記は昨今のソフトウェアの大規模化やフレームワークの流行、実装方式のトレンドなどを鑑みて、ソフトウェア設計者が最も考慮すべきで最も効果の高い項目、といった位置づけで選出したものある。
ある程度の設計経験がある方なら感覚で分かると思うが、実は上記3項目には相関がある。
つまり、テストコードを書くためには、モジュール間が疎結合になっている必要があり、モジュール間を疎結合にするためには適切なモジュール分割が行なわれている必要がある、ということだ。
つまり、テストコードを書くためには、モジュール間が疎結合になっている必要があり、モジュール間を疎結合にするためには適切なモジュール分割が行なわれている必要がある、ということだ。
したがって 1 → 2 → 3 の順に実現していく必要がある。このとき、例えば 2 までしか達成できなくとも、それなりに大きな効果がある。
1. 適切なモジュール分割
説明のためにひとつ身近な例を挙げよう。
一般的な MVC フレームワークをモジュールという観点で考えると、Model, View, Controller にモジュールが分かれている。
一般的な MVC フレームワークをモジュールという観点で考えると、Model, View, Controller にモジュールが分かれている。
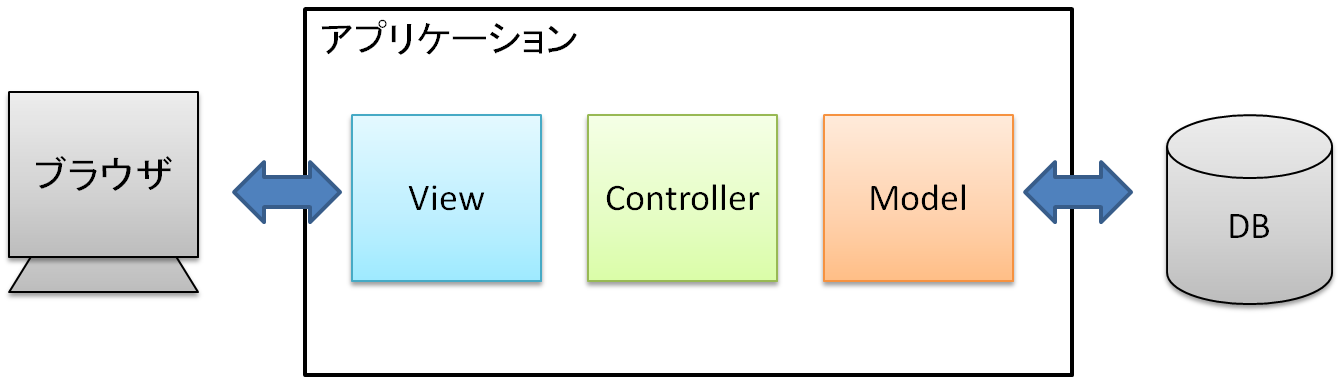
それぞれの役割分担は以下のようになっている。
- M: データアクセス、業務ロジック
- V: 画面の表示、UI
- C: M, V の制御
Model が DB に対応していて(本当はそれだけではない、後述)、Controller から呼び出すわけだが、業務ロジックを直接 Controller に書くのはよくない、みたいな意識をなんとなく持っている人はいるだろうか。
実際、DBアクセス処理や外部APIの呼び出しなどを Controller 内に直接ずらずらと書き連ねていくのはよろしくない。
実際、DBアクセス処理や外部APIの呼び出しなどを Controller 内に直接ずらずらと書き連ねていくのはよろしくない。
※WindowsForms の人は、Form の中にずらずらと業務ロジックを書いてあるような状況と考えて欲しい。
小規模なアプリケーションでは何ら問題ないが、エンタープライズシステムなどといったある程度の規模のソフトウェアでこういう作り方を続けていくと、そのうち Controller が肥大化し、苦しくなってくる(下図)1。
かといって Controller の代わりに Model に業務ロジックを実装していっても、システムの規模が大きくなれば同じように苦しくなってくる。
当然テストを書くことなんて到底不可能だ。
ではどうしたらよいのか。
「サービス」の導入
一つの解決策は、 M, V, C 以外に、S: Service というモジュールを導入することだ2。
Service モジュール内に、業務や機能の分類ごとにサービスクラスを作っていき、業務ロジックはすべてそこに追い出してしまう。
Controller は単にサービスクラスを呼び出すだけ。で、サービスの出力を View に渡したり、処理結果(または例外キャッチ)を元に画面遷移したりという風に本来の Controller の仕事に専念すればよい。
Controller は単にサービスクラスを呼び出すだけ。で、サービスの出力を View に渡したり、処理結果(または例外キャッチ)を元に画面遷移したりという風に本来の Controller の仕事に専念すればよい。
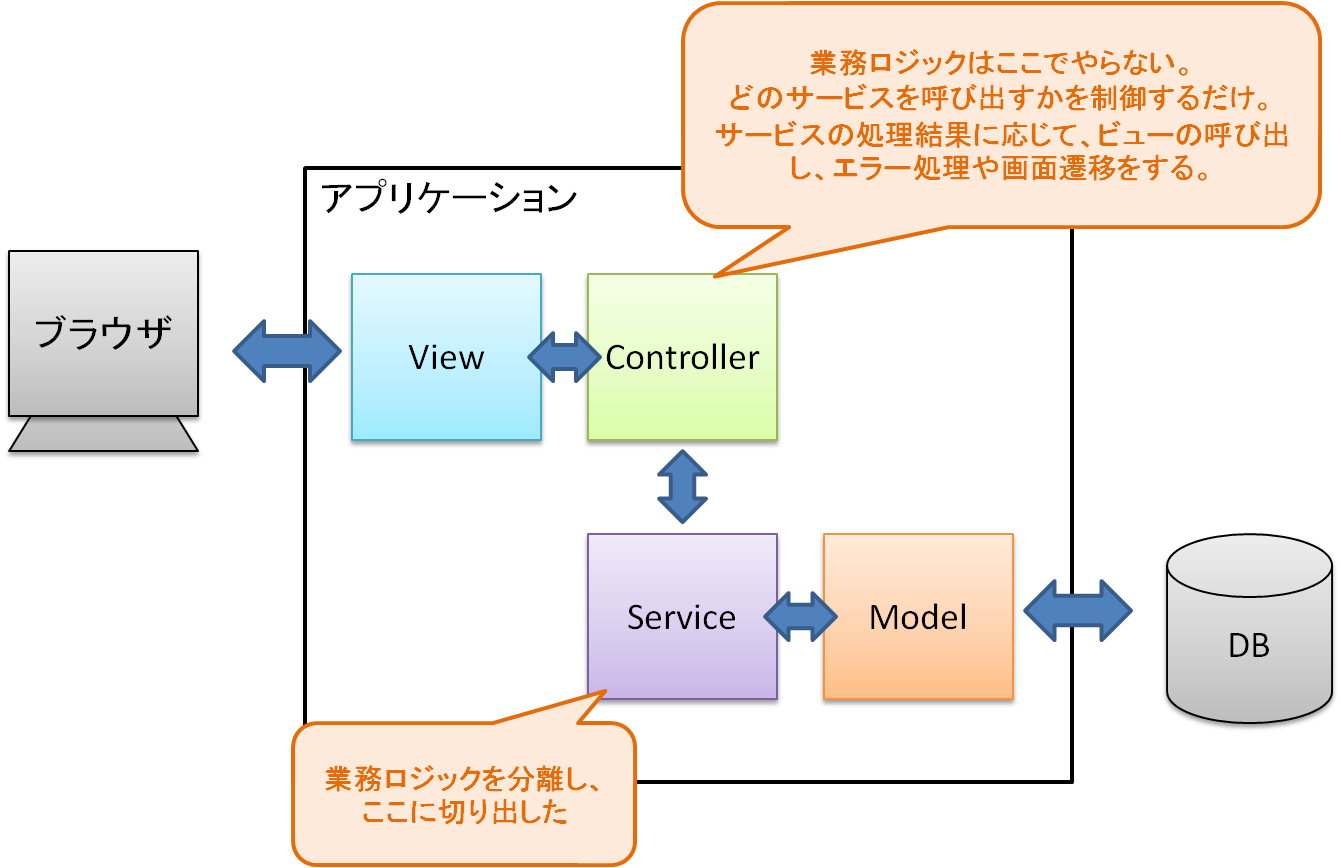
"MVCSアーキテクチャ" という言葉はないのだが、まぁそんなイメージだ。3
注意して欲しいのは、Service モジュールは、View や Controller に依存しないように構成しなくてはならない(後述)。
Model には依存してかまわない4。図の中で Controller の下に Service が描いてあるのはそういう意味でもある。
サービスモデル
こうやって小さなプロダクトを完成させたとして、それを機能拡張して改修して、と続けていくと、サービスモジュール内のあるサービスクラスが大規模化してくることが起こりうる。そしてクラスの入出力データも大規模化してくる。
たとえば、検索処理を行って検索結果一覧を返すサービスがあったとする。
その入力は、検索条件を表す画面からのポストデータ(というか連想配列)で、その出力は Model の配列だったとしよう。
その入力は、検索条件を表す画面からのポストデータ(というか連想配列)で、その出力は Model の配列だったとしよう。
ところが機能拡張により検索条件が複雑化して、入力データが連想配列では苦しくなってくる。
そういうときには、サービスの入力データを表す新しいモデルクラスを定義し、それを使ってデータを受け渡すようにする。
MVCフレームワークの Model とは区別したいので、それぞれに適切な呼び名をつけよう。
ここまでの説明上の流れでは、MVCフレームワークの Model はデータベースモデルを指しているとしているので、これを「EntityModel」と呼ぶ。
そしてサービスの入力データは、なんでも良いのだが、ここでは「ServiceModel」とでもしておこう。
ここまでの説明上の流れでは、MVCフレームワークの Model はデータベースモデルを指しているとしているので、これを「EntityModel」と呼ぶ。
そしてサービスの入力データは、なんでも良いのだが、ここでは「ServiceModel」とでもしておこう。
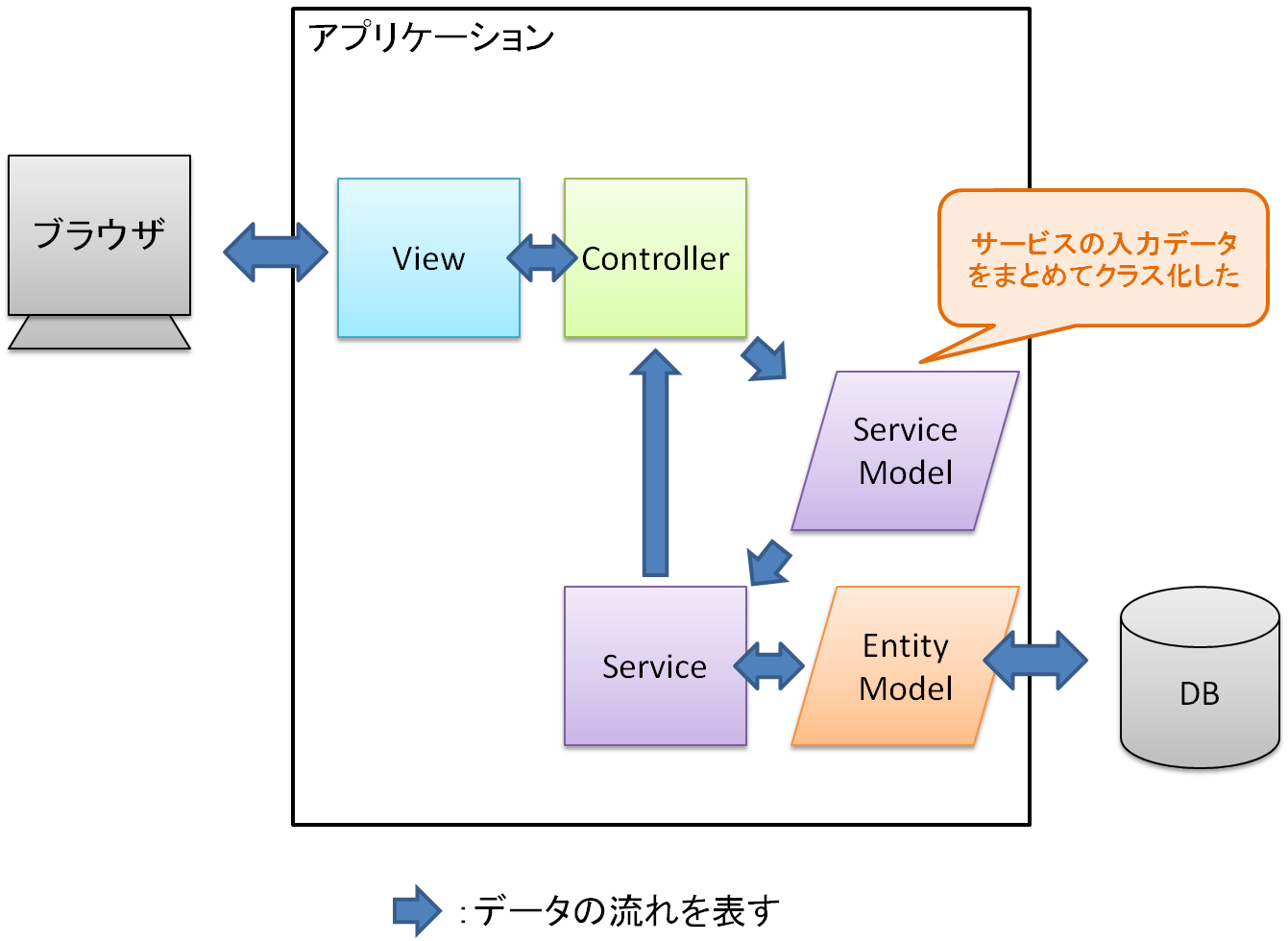
※なお、この図からは Model を表す箱は「データ」を意味する平行四辺形で描くことにした。
視覚的に分かりやすくするためであり、それ以上の深い意図はない。
視覚的に分かりやすくするためであり、それ以上の深い意図はない。
ビューモデル
次に、サービスの出力データが複雑化してくるケースだ。
これもサービスクラスが大きくなってくると当然のように起こりうる。
これもサービスクラスが大きくなってくると当然のように起こりうる。
この場合も同様に、それを表す新しいモデルを定義し、それを使ってデータを受け渡すようにする。
名前は、どうしようか(名前はとても重要だ。いつも命名にそれなりの時間を要する)。
サービスの出力はビューに出力するためのデータであるとすると、「ViewModel」とでも呼ぶことにする。
名前は、どうしようか(名前はとても重要だ。いつも命名にそれなりの時間を要する)。
サービスの出力はビューに出力するためのデータであるとすると、「ViewModel」とでも呼ぶことにする。

ビューモデルを使うアーキテクチャとして MVVM 5 があるが、まさにそれと同じようなイメージだ。この構成は Ajax を使うときにもよくマッチする。 View がブラウザ側で動いているような構成になるが、ViewModel をそのまま Json エンコードしてフロントに返してやれば、VueJS などで直接バインディングするだけで画面に値が反映される。とても分かりやすくなるしラクになるので、オススメのアーキテクチャパターンの一つだ6。
ViewModel という名前に違和感があるなら、違った観点から命名してもよい。
例えば、WebAPI の出力を表しているのなら、WebApiResultModel としてもいいだろう。
例えば、WebAPI の出力を表しているのなら、WebApiResultModel としてもいいだろう。
このように、データの意味に基づいて〇〇モデルというように命名して、入出力データを整理していけばいいのだ。
※(2019-01-02 追記)個人的に Model という言葉は抽象的すぎると思っているので、例えば MVC の M がDBを表しているモデルなら
EntityModel と呼ぼう、みたいに、具体的に〇〇モデルと呼び分ける方が整理しやすくなるし、理解しやすくなると思っている。
この時、サービスの入力と出力を同一のモデルに統合してしまわないこと。
本当に同じ意味のデータならそれで構わないが、意味として異なるのであれば別々のモデルとして定義するべきだ。
たまに見かける失敗例の一つなので、注意して欲しい(僕も何度かやらかした記憶があるが、それは秘密にしておこう)。
本当に同じ意味のデータならそれで構わないが、意味として異なるのであれば別々のモデルとして定義するべきだ。
たまに見かける失敗例の一つなので、注意して欲しい(僕も何度かやらかした記憶があるが、それは秘密にしておこう)。
バッチ処理
さてここで少し視点を変えて、バッチ処理についても考えてみたい。
業務システムに於いて必ずといっていい程存在するのが、スケジュールバッチや夜間バッチなどと呼ばれるいわゆる "バッチ処理" だ。
現場の肌感覚で説明するといった以上、バッチ処理についても触れざるを得ない(こういった現場目線での具体例が専門書には少ないように思う)。
現場の肌感覚で説明するといった以上、バッチ処理についても触れざるを得ない(こういった現場目線での具体例が専門書には少ないように思う)。
MVCに於けるコントローラと同様に、実はバッチ処理についても、バッチ本体に直接業務ロジックをダラダラと書き連ねるべきではない。
業務ロジックはサービスクラスとして分離独立させ、バッチからはそのサービスを呼ぶだけ、という様な構成が好ましい。
つまりバッチ本体は単純なコントローラーと同じような役割となるべきだ。
つまりバッチ本体は単純なコントローラーと同じような役割となるべきだ。
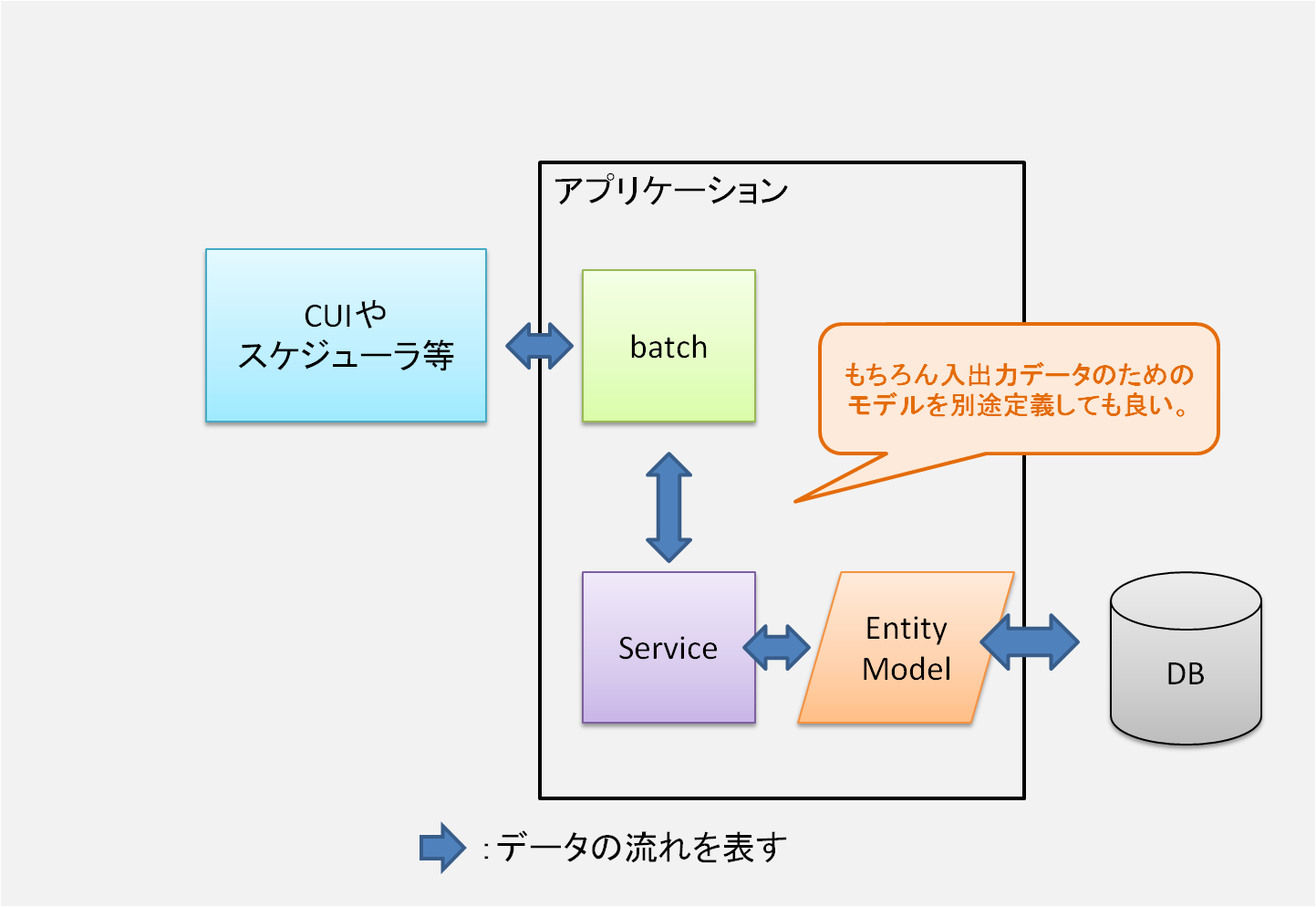
こうすることで、バッチ処理についてもアーキテクチャの統一感をもたらし、モジュール間の疎結合を実現し、テストコードで保護するための基本構成が得られるようになる。
2. 依存関係を一方向にする
まず依存関係について少し掘り下げて説明しておこう。
あるクラス
クラスだけでなくモジュールに於いても同様に依存関係を考えることが出来る。
A とクラス B があるとする。A が B を利用(呼び出しや参照)しているとすると、A は B に依存していることになる。次に、B からは A を一切利用していないとすると、B は A に依存していないことになる7。クラスだけでなくモジュールに於いても同様に依存関係を考えることが出来る。
先程少し触れたように、Service は View や Controller に依存しないようにしなくてはならない。
つまり、各モジュールは下位のモジュールにのみ依存するようにして欲しい。
言葉で説明するとイマイチぴんと来ないかもしれないので、下図を参照して頂きたい。
これまで提示してきた図を、モジュールごとの上下関係(レイヤー)と依存関係に着目して書き直してみたものだ。
これまで提示してきた図を、モジュールごとの上下関係(レイヤー)と依存関係に着目して書き直してみたものだ。
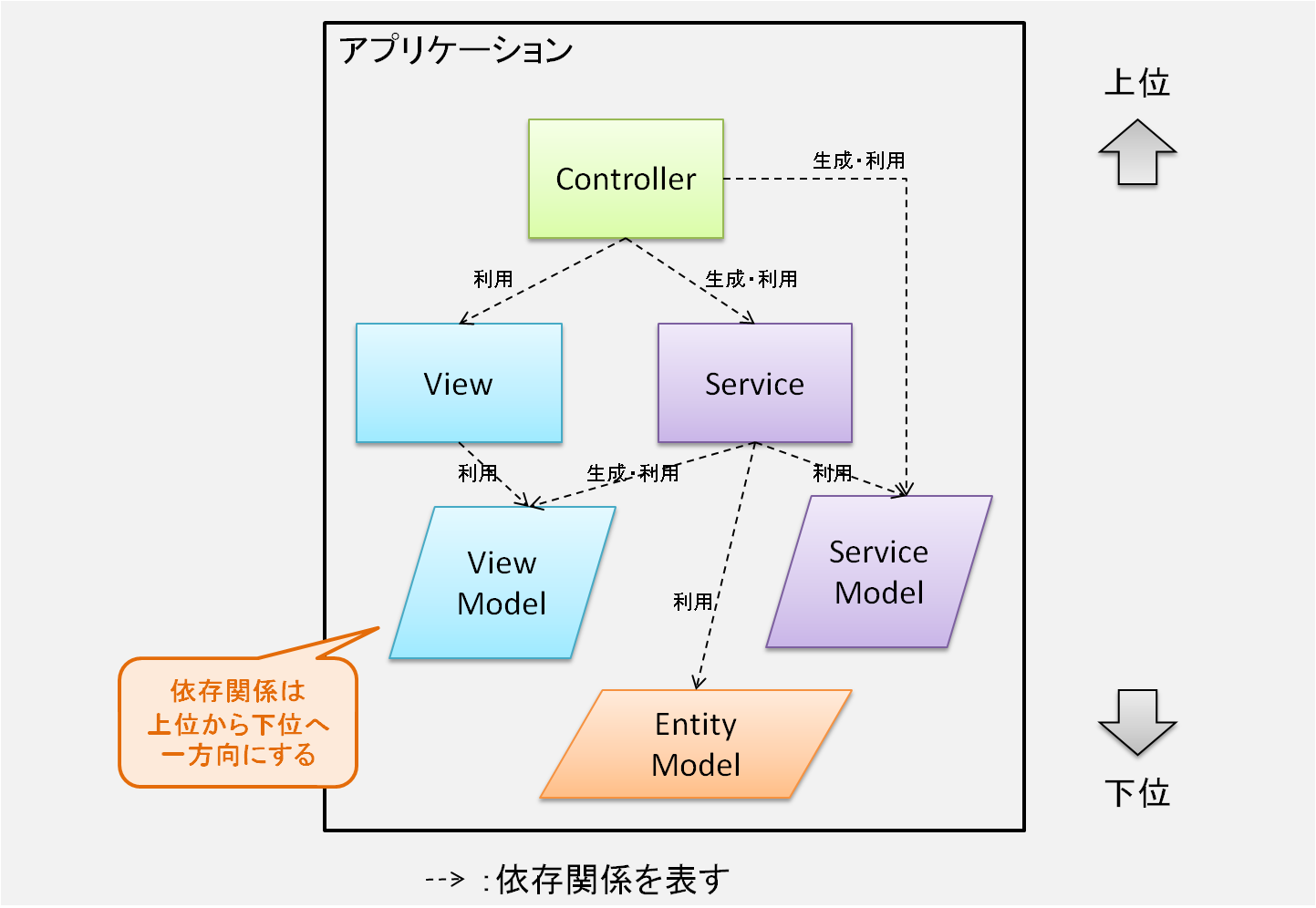
このように、図の上の方にあるモジュールから下にあるモジュールを参照したり呼び出したりするのは構わないが、その逆はダメだ。
また、同列のモジュール間で相互に依存するようなことが無いように注意する8。
モジュール間(そしてクラス間)の依存関係を上から下へ一方向にし、レイヤーを構成させるわけだ。
要点としては、ある下位のレイヤー(とその下)だけを取り出して、その部分だけでも構造が成り立つような仕組みになっている必要がある。
例えば Service とその依存関係にある下位のモジュール(ServiceModel, ViewModel, EntityModel)を取り出して、その部分だけで構造が成り立つようになっているのが分かるだろうか9。
これがもし、Service から Controller への依存があったりすると、そうはいかない。Controller と Service が奇麗に分離されていないということになる。
例えば Service とその依存関係にある下位のモジュール(ServiceModel, ViewModel, EntityModel)を取り出して、その部分だけで構造が成り立つようになっているのが分かるだろうか9。
これがもし、Service から Controller への依存があったりすると、そうはいかない。Controller と Service が奇麗に分離されていないということになる。
3. テストコード
ここまでの構成が出来れば、とりあえずテストコードを書くことが出来る。
サービスクラスが下位のモジュールにしか依存していないので、そこだけ切り出してきて全く別のコードベースから呼び出すことが出来るはずだからだ(下図)10。
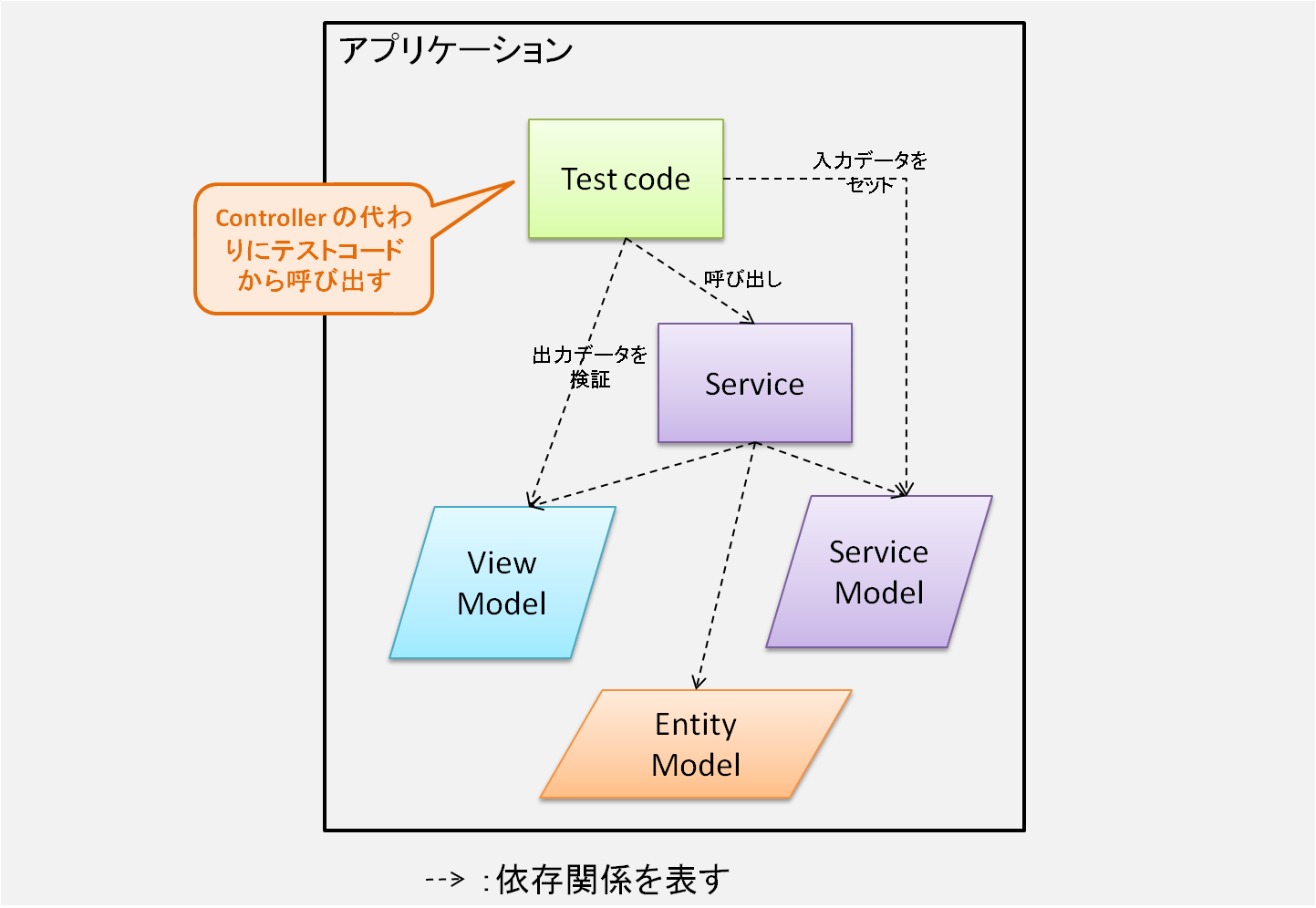
これまでモジュール分割だの依存関係だのと厳しい制約のもとソフトウェアの構造を整理してきた目的は、ここにある。
テストコードを書くことのメリット
今さらかもしれないが、テストコードを書くことのメリットをおさらいしておこう。
- コード修正の度にデグレが発生していないか、何度でもテストを実行して検証することができる11
- テストが必ず通る状態でリリースするため、品質が向上する
- テストコードを書くこと自体にコストがかかるが、長い目で見ると全体的なコストは必ず下がる
- テストコードを読むことでそのクラスの使い方(仕様)が分かる
- 開発チームからすると、テストが通っているという絶対的な安心感
- そもそもテストコードを書ける構造になっていることに価値がある
最後の項目が、最初に述べた 1, 2, 3 の相関関係の裏返しとなっている。
つまり、奇麗な構造になっていないとテストが書けないのだ。
つまり、奇麗な構造になっていないとテストが書けないのだ。
しかしながらテストコードのないソフトウェアが依然として多い。大規模SIプロジェクトや、パッケージソフトではそのほとんどがテストコード無しという現状である。
一方で、テストコードを書かない文化というものもあるようで、あえてそのような選択をしている開発チームであればテストは書かなくてもよいと思う。しかし、テストを書いたこともないのに書かない選択をしているとしたら、是非この機会にチャレンジしてみて欲しい。
特に、プロダクトの初期構築の段階に携わっている場合は、テストコードを導入するチャンスだ。最初にテストコードが書ける構造を整備してテストを書いておかないと、後になってからテストを導入することは非常に骨の折れる作業なのだ。理由は、先述の通りソフトウェアの構造が奇麗になっていないとそもそもテストが書けないため、構造改革に甚大な労力を要するためだ。それを裏返せば、テストコードを維持し続けることでソフトウェアの構造が奇麗に保たれる、という効果が得られるのだ12。
サービス間の依存関係への対処
さて話を続けよう。プロダクトの構築が終わって、さらに開発が続いていったとして、コードベースが発展し大規模化してくると、サービスクラスが多くなりサービス間の依存関係が増えてくる。その度に、それらの依存関係を少しづつ減らしていく努力が必要だ。そうしないと、テストコードを書くのがだんだん苦しくなってくる。
例えばインスタンス生成の依存関係を解消するにはいくつか対応策があるが13、それらの詳細な解説は他のサイトにお任せするとして、ここでは利用の依存関係を解消するために(王道とも言われる)インターフェースを抽出する方法を説明する。
依存したサービスを切り離す
説明のための例として、ここに「商品受注サービス」があるとする。これは読んで字のごとく商品の受注処理を行うビジネスロジックだと思って欲しい。
そしてその中では、受注データの納期をセットするために「納期検索サービス」を呼び出しているとする。
これらの依存関係を図で表すとこうなる。
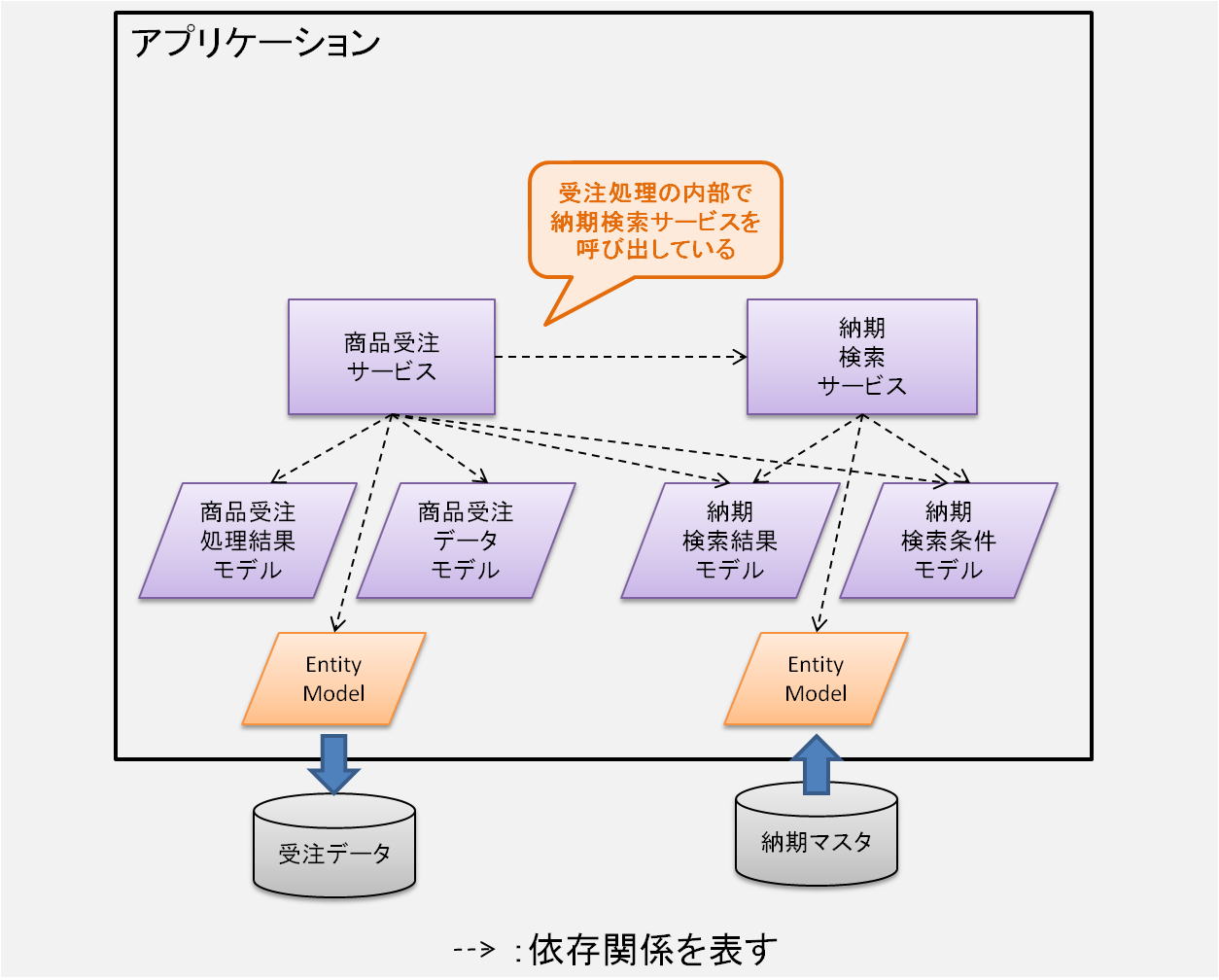
ここで「商品受注サービス」のテストを書くことを考えてみよう。
このサービス(クラス)のテストを書くためには、内部で利用している納期検索サービスのためのデータ(例えば納期マスタ)を用意しておく必要がある。そうなるとテストコードを書く量が増えることになる。
それに納期検索サービスにバグがある状態だったり、開発工程の関係でまだ実装されていないサービスだったりするかもしれない。
それに納期検索サービスにバグがある状態だったり、開発工程の関係でまだ実装されていないサービスだったりするかもしれない。
そもそもこれは単体テストというより、結合した状態でのテストになってしまっているのだ14。
テストコードを書く負荷を減らすためには、テストの粒度を下げる必要がある。すなわち何とかしてこれを単体テストにする必要がある。
そこでインターフェースの出番だ。
インターフェースの抽出
まず納期検索サービスの中で必要なメソッドをインタフェースに抽出する。
そして「商品受注サービス」から「納期検索サービス」に依存するのではなく、そのインタフェースに依存するように変更する(下図)15。
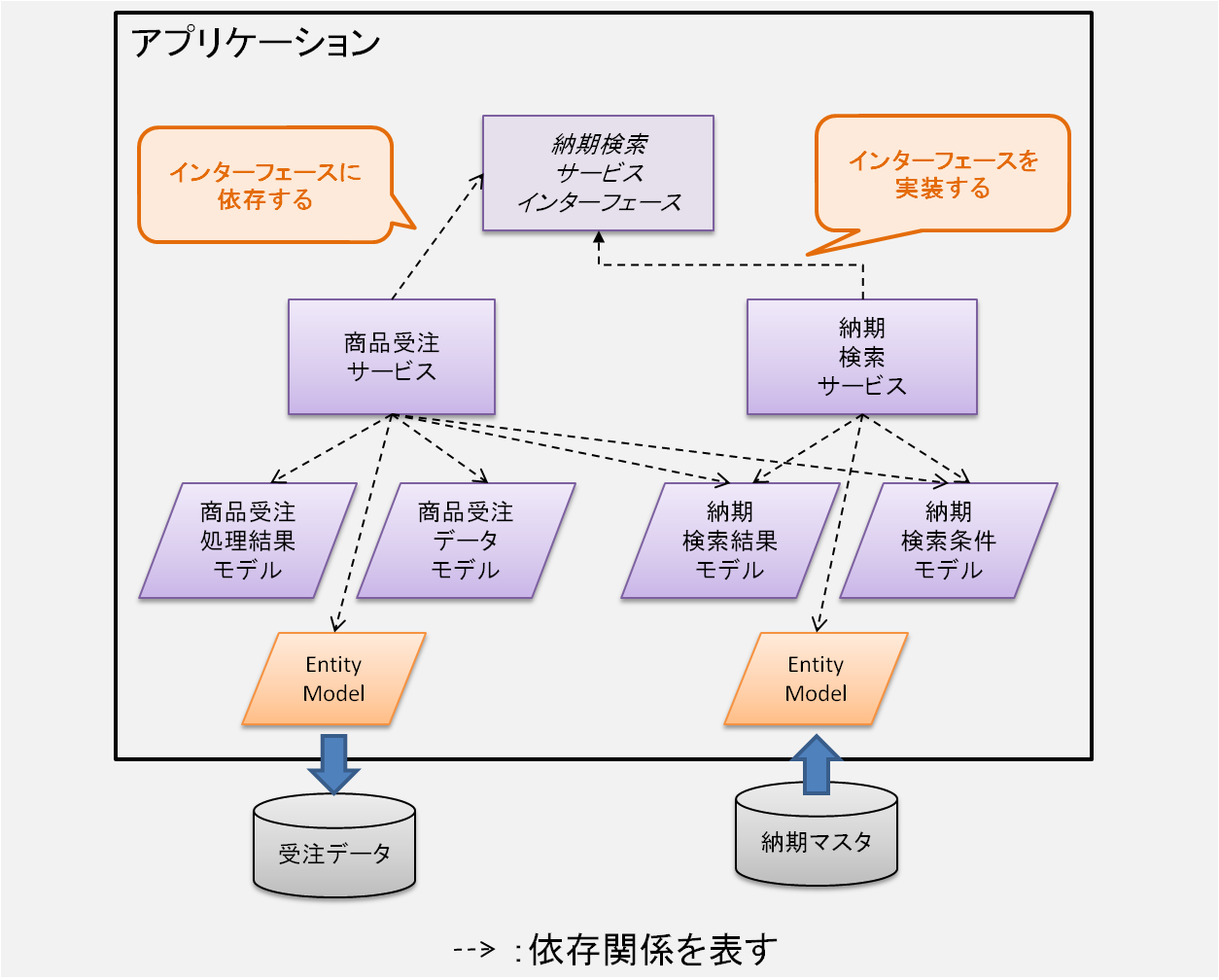
これで果たして、単体テストが書けるようになる。
この後は、サンプルとして C# での実装例まで見てみてほしい。Java でも大体同じような感じだ。
この後は、サンプルとして C# での実装例まで見てみてほしい。Java でも大体同じような感じだ。
C# での例(簡易テストコード)
いざテストを書くと言っても、書いたことない人にとっては全くどうしていいのか分からないことと思う。
Qiitaを読んでいるような意識高い系の人はそんなことないのかも知れないが。
Qiitaを読んでいるような意識高い系の人はそんなことないのかも知れないが。
まず心理的ハードルを下げるために一言いっておくと、重厚長大なテストフレームワークを無理に使う必要はないのだ。
エンタープライズアプリケーションの開発現場に於いて、テストフレームワークを新規導入するには時間と手間がかかるし、開発チームの他のメンバーに使い方を覚えてもらうための学習コストもかかるし、テストコードの書き方や適用範囲などの標準化まで考慮しないと、実際にテストコードを書く運用を始めることは難しいだろう(あと、大人の事情によって色々ハードルがありますよね)。
エンタープライズアプリケーションの開発現場に於いて、テストフレームワークを新規導入するには時間と手間がかかるし、開発チームの他のメンバーに使い方を覚えてもらうための学習コストもかかるし、テストコードの書き方や適用範囲などの標準化まで考慮しないと、実際にテストコードを書く運用を始めることは難しいだろう(あと、大人の事情によって色々ハードルがありますよね)。
ここでは、簡易的にテストコードを書く方法もあるということを紹介するため、本質とはズレるかもしれないが、テストフレームワークを使わずに独立した実行モジュールを自作することでテストを書いてみる。C# を選択したのは好みの問題だ。
Javaでいうところの main() 関数を含むクラスを自分で書いて、コンパイルして
java コマンドで実行する、.NET でいうところのコンソールアプリケーションを作って .exe を実行する、みたいなイメージだ。
納期検索サービス
// 納期の検索条件
public class DeliveryScheduleSearchConditionModel
{
public string ProductCode { get; set; } // 商品CD
}
// 納期の検索結果
public class DeliveryScheduleSearchResultModel
{
public DateTime DeliveryScheduleDate { get; set; } // 納期日付
}
// 納期検索サービスを表すインターフェース(本当のオブジェクト指向なら商品受注サービスの方に置く)
interface IDeliveryScheduleSearchSvc
{
// 検索処理
DeliveryScheduleSearchResultModel Search(DeliveryScheduleSearchConditionModel cond);
}
// 納期検索サービス
public class DeliveryScheduleSearchSvc : IDeliveryScheduleSearchSvc
{
// 検索処理の実装
public DeliveryScheduleSearchResultModel Search(DeliveryScheduleSearchConditionModel cond)
{
// 省略
}
}
商品受注サービス
// 商品受注サービスの入力データ
public class ReceiveOrderInputModel
{
public string ProductCode { get; set; } // 商品CD
public decimal Quantity { get; set; } // 数量
public decimal Amount { get; set; } // 価格
// 他にもいっぱい
}
// 商品受注サービスの処理結果
public class ReceiveOrderResultModel
{
public ReceiveSatus Status { get; set; } // 受注状態
public DateTime DeliveryScheduleDate { get; set; } // 納期
}
// 商品受注サービス
class ReceiveOrderSvc
{
IDeliveryScheduleSearchSvc _deliveryScheduleSearchSvc; // 納期検索サービスのインターフェース
// コンストラクタ
public ReceiveOrderSvc(IDeliveryScheduleSearchSvc deliveryScheduleSearchSvc)
{
this._deliveryScheduleSearchSvc = deliveryScheduleSearchSvc;
}
// 受注処理
public ReceiveOrderResultModel Exec(ReceiveOrderInputModel input)
{
// 前処理(省略)
// 納期検索サービスの入力データを作る
var deliveryScheduleSearchcond = new DeliveryScheduleSearchConditionModel
{
ProductCode = input.ProductCode
};
// 納期検索サービスを呼ぶ
var searchResult = _deliveryScheduleSearchSvc.Search(deliveryScheduleSearchcond);
// 他にもいろいろ処理(省略)
return new ReceiveOrderResultModel
{
DeliveryScheduleDate = searchResult.DeliveryScheduleDate // 納期検索サービスの出力データを使う
};
}
}
テストコード
// テストコード(コンソールアプリケーション)
class TestProgram
{
// テスト用の納期検索サービス(モック)
class DeliveryScheduleSearchSvcForTest : IDeliveryScheduleSearchSvc
{
// 検索条件
public DeliveryScheduleSearchConditionModel Cond;
// 検索処理
public DeliveryScheduleSearchResultModel Search(DeliveryScheduleSearchConditionModel cond)
{
this.Cond = cond; // 引数を保存(テストコードで内容を検証できるように)
// 都合のいいようにデータを作って返却する
return new DeliveryScheduleSearchResultModel
{
DeliveryScheduleDate = new DateTime(2018, 12, 7)
};
}
}
static void Main(string[] args)
{
// 初期化処理(フレームワークやデータベースの初期化など)
// 納期検索サービスのモックを作る
var mock = new DeliveryScheduleSearchSvcForTest();
// 商品受注サービスの入力データ
var input = new ReceiveOrderInputModel
{
// 受注内容をセット
};
// 商品受注サービスにモックを渡してインスタンス生成
var targetSvc = new ReceiveOrderSvc(mock);
// 商品受注サービスを呼び出す
var result = targetSvc.Exec(input);
// 結果を検証
AssertEqual(ReceiveSatus.SUCCESS, result.Status);
AssertEqual(new DateTime(2018, 12, 7), result.DeliveryScheduleDate);
// 以下、result の内容を検証する
}
// 検証用のメソッド(あくまで簡易な実装例。本当はもっと考慮すべきことがある)
static void AssertEqual(object expected, object actual)
{
if (!object.Equals(expected, actual)) throw new Exception($"Assertion error! expected: {expected}, but actually: {actual}");
}
}
こんな風に自力でテストを書けるはずだ16。
余談になるが、Rubyなどのダックタイピングが出来る言語で同じような構造を考える際にはインターフェースを明示的に定義することはないが、僕の頭の中ではインターフェースがあるものとしてクラスを構成しているような感触がある。
動的言語の力によりインターフェースを定義しなくてよいのでコードの記述量が少なくなり、慣れればスッキリした気分で書けるが、その裏を返せば頭の中にインターフェースが見えない人にとっては、理解に時間を要したり、そもそも理解できないこともあるのだろうと思う。
そういう意味では、開発者のレベルに応じてプログラミング言語を選定することも大切なんだなと思う。
動的言語の力によりインターフェースを定義しなくてよいのでコードの記述量が少なくなり、慣れればスッキリした気分で書けるが、その裏を返せば頭の中にインターフェースが見えない人にとっては、理解に時間を要したり、そもそも理解できないこともあるのだろうと思う。
そういう意味では、開発者のレベルに応じてプログラミング言語を選定することも大切なんだなと思う。
あとがき
変更に強いアーキテクチャの本質は、テストフレームワークを使うことでも、優秀な設計ツールを使うことでもない。
これまで見てきたように、適切にモジュール分割をして依存関係を整理し、それらをテストコードで保護していく事が本質だ。
それを実施するために必要な概念を整理して知識としてまとめたものがオブジェクト指向設計論であり、テストフレームであり、ドメイン駆動開発などの方法論だと僕は思っている。
方法論だけを論じても意味がない。本質を見極めて、現実世界での困りごとに適切に適用できるようになりたいものだ。
これまで見てきたように、適切にモジュール分割をして依存関係を整理し、それらをテストコードで保護していく事が本質だ。
それを実施するために必要な概念を整理して知識としてまとめたものがオブジェクト指向設計論であり、テストフレームであり、ドメイン駆動開発などの方法論だと僕は思っている。
方法論だけを論じても意味がない。本質を見極めて、現実世界での困りごとに適切に適用できるようになりたいものだ。
そうはいっても、テストフレームワークを使う方がずっと楽にテストが書けて運用しやすいので、自力で実装する例はあくまでお試し、こんなことも出来ますよ、という参考までにとどめておいて欲しい。一般的に流行しているようなフレームワークはとりあえず触れてみるなどして、継続して自分の知識をアップデートしていくべきだ。
ここまで、3ステップでの施策として構造設計の課題点と解決策を駆け足で見てきたが、そもそもそれらをどこまで適用するかの見極めも重要である。小規模でラピッドなプロトタイプ開発であれば、最初からコントローラに全部処理を書いてしまってもいいし、中規模まで発展することを見込むなら、ユニットテストだけでなくインテグレーションテストまで最初から用意する、みたいにケースバイケースで判断していくしかない。これにはやはりある程度の経験が必要だろう。
また、この記事では出来るだけ専門用語を避け、平易な表現で説明してきたが、向学の志がある方のために注釈にて専門用語の紹介を書いておいた。興味があれば自分で調べてみて欲しいと思う。
長くなったが、この記事によって一人でも多くの人が「テストコードを導入してみよう」と思うキッカケになれば幸いに思う。
現場からは以上だ。
- Fat Controller とも呼ばれ、アンチパターンの一つだ ↩
- Service という言葉には別の意味があるかもしれないが、SOA(サービス指向アーキテクチャ)という考え方があり、システムの規模が巨大化していくにつれて最終的には SOA に近い形態を目指すこととなるため、僕は最初からサービスという概念で設計していっている。 ↩
- ここでいうサービスモジュールは、DDD(ドメイン駆動設計)ではドメインモデルという言葉で表されるものだ。 ↩
- 本当はデータアクセスを抽象化する「リポジトリパターン」というアーキテクチャパターンもある。とりあえずここではテストコードからも実際のDBにアクセスする前提としている。 ↩
- Model-View-ViewModel アーキテクチャ。Microsoft の WPF を始めフロントエンドライブラリでよく用いられる。DBに対応した Model とは別に、View に対応した ViewModel を用意し、画面項目にバインディングするような考え方。 ↩
- この場合は MVC フレームワークの View はほぼ使わないことになる。VueJS や AngularJS などのフロントエンドで MVVM を実現するフレームワークを導入するなら、バックエンドは WebAPI としての役割に徹する方が分かりやすくなる。 ↩
- 依存関係には度合いがあり、例えばUMLではクラスの継承(is-a), インスタンス生成(create)、所有(has-a)、利用(uses-a)というように分類わけされている。このうち利用(uses-)が最も弱い依存関係だとされており、インスタンス生成(create)は最も強い結合、プログラミング言語でいう new する事にあたる。new するには相手の実体を知っている必要があるためだ。 ↩
- 循環参照といってアンチ設計パターンの一つだ ↩
- クリーンアーキテクチャという概念がこれに近い。実際、クリーンアーキテクチャという言葉は最近知ったので、それに影響を受けているわけではない。自分の勉強不足に反省。。。 ↩
- テスト用にDBを分けて、テストコードからテスト用DBにアクセスするというやり方になる。本当はもっと色々考慮した方がいい事があるのは重々承知であるが、とりあえずテストコードを書くことは出来る状態になっている、ということの本質をここでは伝えたい。 ↩
- リグレッションテスト(回帰テスト)という ↩
- "奇麗" の基準に個人差があるので賛否両論あるところかと思うが、少なくともここで言わんとしているモジュール分割と依存関係の一方向性は維持できるはずと考えている ↩
- 興味のある方は ファクトリーパターンや、DI(Dependency Injection: 依存性の外部注入)などのキーワードでググってみて欲しい。 ↩
- もちろん結合テストのためのテストコードというものも存在する。Selenium などのテストフレームワークでは、ブラウザを実際にテストコードで操作してUIからバックエンドまでモジュール結合した状態でシナリオテストを行うようなことが出来る。インテグレーションテスト、e2eテスト(End to End Test)というキーワードで調べてみよう。 ↩
- オブジェクト指向でいう依存関係逆転の原則である。その原則に厳密に従うなら、インタフェースは実は商品受注サービスの側のモジュールに属している必要がある。 ↩
- なお、サンプルコード中にコメントで書いてあるように、実際にはフレームワークの初期化やDBの初期化などのお膳立てが必要となる。例えば EntityFramework なら App.config を用意するだけで何とかなるし、高級なフレームワークほど外部コードから呼び出すための手順などが整備されているようなので、詳細はフレームワークのドキュメントを参照されたい。実際、Java の Play2 + JPA の案件でこのようにして自力で簡易テストコードを書いたりしたことがあった。 ↩
from https://juejin.im/post/5d66a4875188250d9432a973
软件架构万字漫谈:业务架构、应用架构与云基础架构
from http://www.uml.org.cn/zjjs/2016052302.asp
在首席架构师手里,应用架构如此设计
| |||||
| |||||
| |||||













留言
張貼留言